微信公众号

手机端

搜索




 从HoloLens中SLAM技术揭秘(上)的小测试里,我们知道,“我在哪儿(定位)”“我周围有什么(三维场景重建)”离不开环境感知摄像头。HoloLens的定位不依赖深度摄像头,而对周围三维环境构建也不仅仅依赖深度摄像头。那么问题来了,环境感知摄像头是怎么知道HoloLens在空间中的位置呢?深度摄像头又是如何重建三维场景呢?这就涉及到SLAM了。
SLAM作为一个三维感知的基础技术并不新鲜,SLAM从提出到现在已经三十多年,用于解决实现机器人的自主定位和导航。微软的SLAM项目早在2001年11月5日就创立了。目前SLAM体系发展已经相当庞大。
从HoloLens中SLAM技术揭秘(上)的小测试里,我们知道,“我在哪儿(定位)”“我周围有什么(三维场景重建)”离不开环境感知摄像头。HoloLens的定位不依赖深度摄像头,而对周围三维环境构建也不仅仅依赖深度摄像头。那么问题来了,环境感知摄像头是怎么知道HoloLens在空间中的位置呢?深度摄像头又是如何重建三维场景呢?这就涉及到SLAM了。
SLAM作为一个三维感知的基础技术并不新鲜,SLAM从提出到现在已经三十多年,用于解决实现机器人的自主定位和导航。微软的SLAM项目早在2001年11月5日就创立了。目前SLAM体系发展已经相当庞大。

[图片1 SLAM主要研究方法 来自 bbsmax-yhexie 《SLAM学习笔记(2)SLAM算法》]
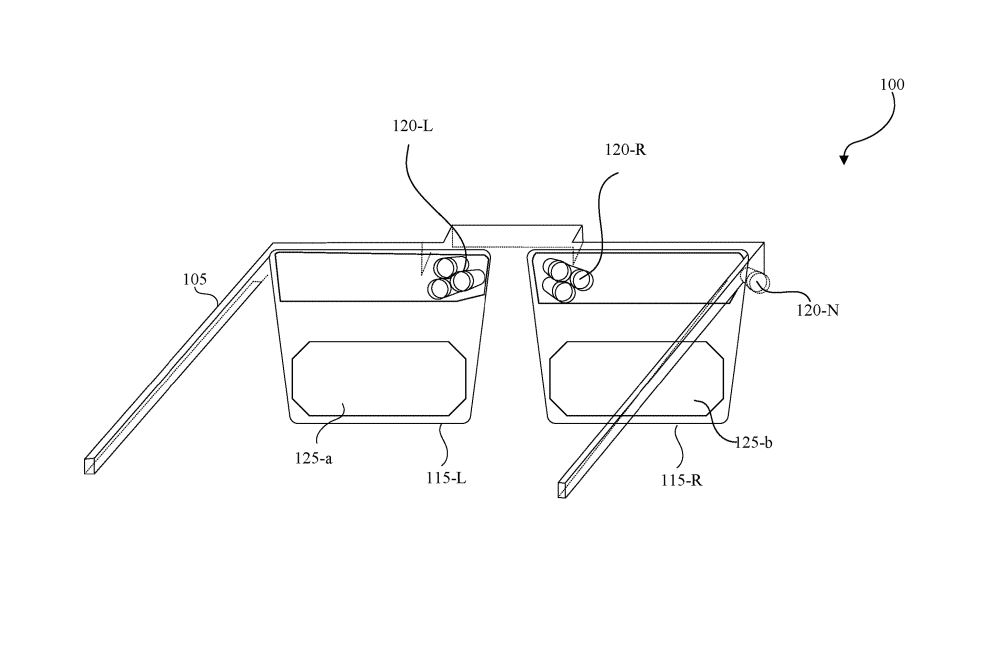
今天我们只谈HoloLens使用的技术,就是摄像机里的单目视觉和RGBD类。 单目视觉,就是依靠一个摄像头去完成SLAM。HoloLens有4个环境感知摄像头,仔细看下,你会发现,靠内的两个摄像头朝向前方,靠外的两个摄像头分别朝向左右两边。主要起作用的是靠内的摄像头,只要靠内的摄像头有一个不被遮挡,即使其他三个摄像头被遮挡,也不会影响HoloLens对空间位置的感知。HoloLens正是用单目SLAM。首先提取图像中的特征,然后根据相邻帧图像的特征去匹配,识别出场景某些特征点位置,并通过图像的变化反向计算出相机的运动。
[图2 相机位置追踪 来自 极客头条-张哲《SLAM刚刚开始的未来》]
由于有深度摄像头,HoloLens并不需要靠环境感知摄像头去获得场景每个像素的深度值,只需要根据一些匹配上的关键特征点计算出摄像头相对场景位置即可。否则仅仅依靠环境感知摄像头计算场景所有深度信息,代价相当大。 RGBD类。最大的特点是可以通过红外结构光或Time-of-Flight原理,直接测出图像中各像素离相机的距离。因此,它比传统相机能够提供更丰富的信息,也不必像单目或双目那样费时费力地计算深度。HoloLens的深度摄像头用的便是Time-of-Flight原理,即通过从投射的红外线脉冲反射回来的时间来获得Depth的信息。由于使用红外线,也正是为什么HoloLens对黑色表面识别不好的原因。 HoloLens的三维场景重建利用的是Richard Newcombe发明的Kinect Fusion。为了更好理解Kinect Fusion,可以想象下,我们在玩雕塑。先是有一个巨大的方块,我们一个角度去挖,挖到想要成型样子的表面就不挖了。挖多深,用的就是深度图的信息。然后不断换角度,继续重复上面的,这样多个角度后,雕塑的样子慢慢浮现出来。 具体重建三维场景流程如下图。
[图片3 来自 Microsoft Developer Network]
a)读入的深度图像转换为三维点云并且计算每一点的法向量。 b)相机的追踪。Kinect Fusion是计算得到的带有法向量的点云,和通过光线投影算法根据上一帧位置从模型投影出来的点云,利用 ICP 算法配准计算位置,但深度摄像头的精细度并不高,如果HoloLens采用深度图数据来计算HoloLens位置,误差会挺大,全息场景也不会稳定固定在空间里。相机的位置用的是环境感知摄像头计算出来的。 c)根据相机的位置,将当前帧的点云融合到网格模型中去。 d)根据当前帧相机位置利用光线投影算法从模型投影得到当前帧视角下的点云,并且计算其法向量,用来对下一帧的输入图像配准。 如此是个循环的过程,通过移动相机获取场景不同视角下的点云,重建完整的场景表面。 现在,你应该对HoloLens中SLAM技术的使用有个清晰的认识了吧! 目前对SLAM的研究依然还在继续,由于产品和硬件高度差异化,而SLAM相关技术的整合和优化又很复杂,导致算法和软件高度碎片化,市场上真正能在实际应用中运用SLAM的产品不多。而能够将IMU 、环境感知摄像头、深度摄像头各取所长,完美融合在一起,这里要给我软硬实力手动比心。 相关链接: HoloLens中SLAM技术揭秘(上) 来源:微软HoloLens 关注微信公众号:VR陀螺(vrtuoluo),定时推送,VR/AR行业干货分享、爆料揭秘、互动精彩多。投稿/爆料:tougao@youxituoluo.com
稿件/商务合作: 林南(微信 19250561593) 六六(微信 13138755620)
加入行业交流群:林南(微信 19250561593)

元宇宙数字产业服务平台
下载「陀螺科技」APP,获取前沿深度元宇宙讯息
























.jpg)